The Lore of Q-Learning
The Story begins with RL…
RL (Reinforcement Learning) is like trying to teach a computer the difference between good and bad choices.
The computer is called an agent. It looks at where it is (state), what it can do (action), and gets a score (reward) that “teaches” it about the actions consequences (good or bad).
 Example: A robot in a maze. If the distance to the charging station doesn’t keep decreasing, it must restart from the starting point. Over time, it learns which actions move it closer to the station and which ones cause a restart.
Example: A robot in a maze. If the distance to the charging station doesn’t keep decreasing, it must restart from the starting point. Over time, it learns which actions move it closer to the station and which ones cause a restart.
The antagonist appears!
Exploration-Exploitation dilemma:
Exploration → Trying something new to know if it’s better than the usual.
Exploitation → Sticking with the usual.
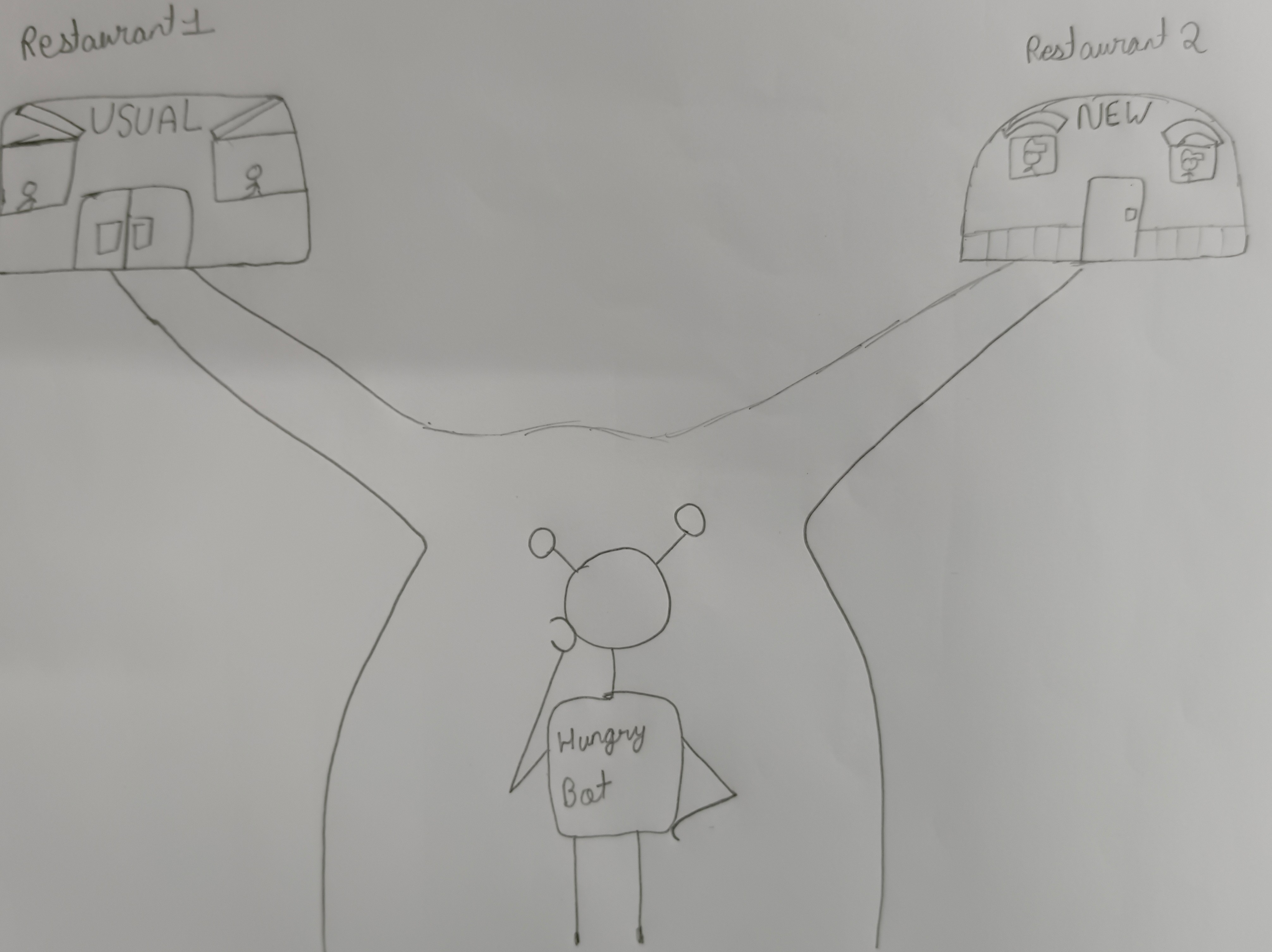 Example: A hungry bot deciding where to eat. It can eat at the usual place (exploitation) or try out a new place (exploration). Only by exploration can it find better food.
Example: A hungry bot deciding where to eat. It can eat at the usual place (exploitation) or try out a new place (exploration). Only by exploration can it find better food.
Lessons from a drunken master
Off-Policy Learning:
Doing lots of random stuff, some bad, some good, but when learning from it, focusing more on the good! (updates its knowledge using the best possible action, even if that’s not the one it chose)
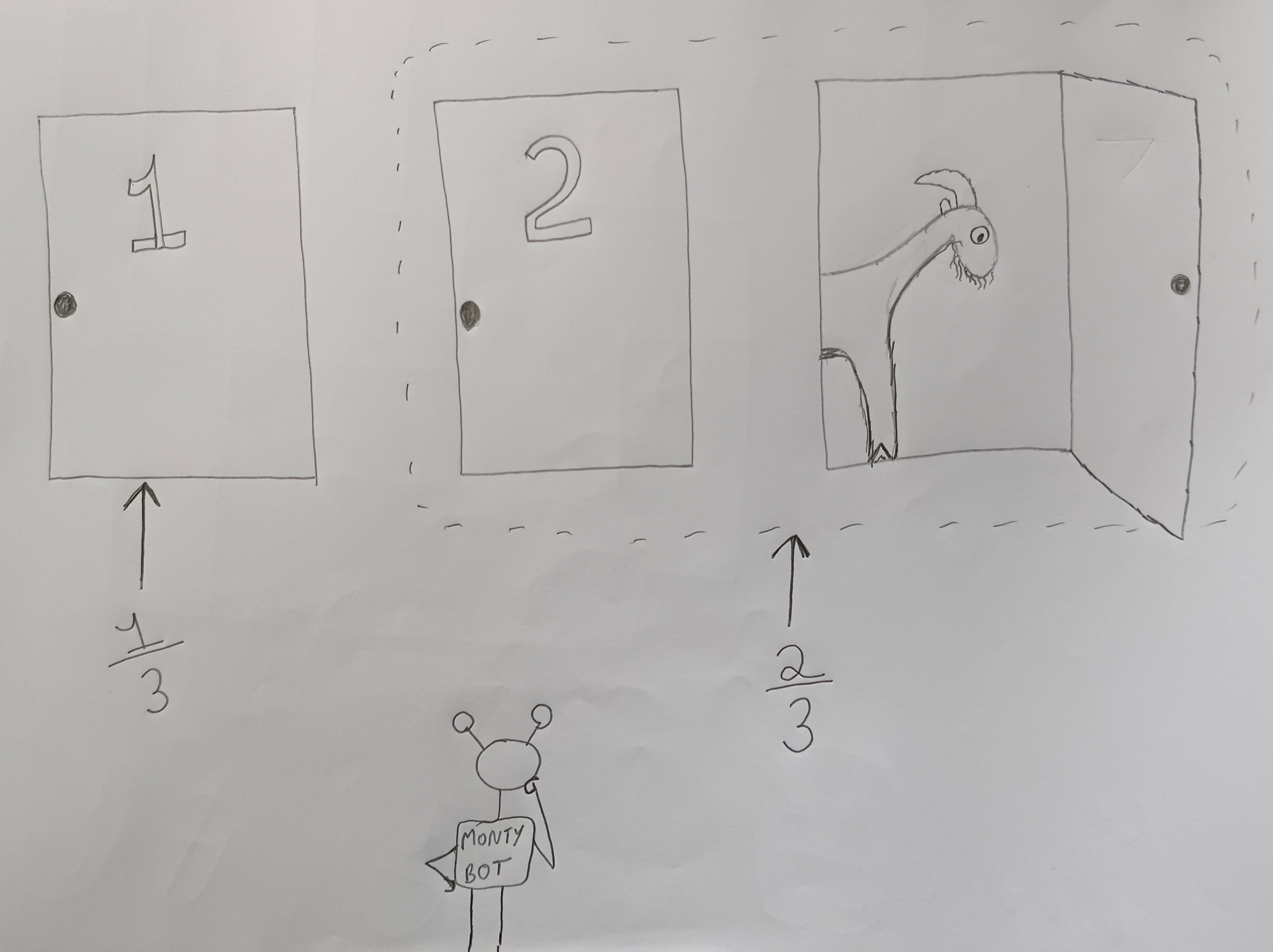 Consider the Monty Hall problem:
Consider the Monty Hall problem:
3 Doors, one has a car and the other two have goats. The RL agent picks a door(say number 1) and Monty opens one of the doors(say number 3) to reveal a goat, now the agent is given a choice either to switch to the number 2 door or stay at number 1. Staying has a probability of ⅓ that it has a car while switching increases that probability to ⅔ . So, always switching is the best policy!
In off-policy, even if the agent chooses to stay, it still learns that switching is better.
Our protagonist learns self-control
Temporal Difference (TD) Control:
Learning that switching is better in the above example requires comparing the value of both choices. If an action has not been tried yet, the agent cannot know its reward exactly. It has to estimate the value of all actions based on expected future rewards. TD control enables this by updating action values step by step using the current reward plus the agent’s best guess of future rewards.
THE GREAT WAR
Q-Learning = Off-policy + TD-control
Q -> Quality (quality of action in a state) It teaches an agent how good a certain action is in a certain state.
The agent keeps an internal Q-Table, basically the Q table tells the agent that doing this action in this particular state will ‘probably’ give you this much reward. TD-control and off-policy decide how the values inside that table update. TD control updates step by step using rewards plus future estimates. Off-policy means it updates toward the best possible action, even if the agent chose something else.
The process is:
This is the formula that updates the Q-Table:
The immediate reward rₜ₊₁ plus an estimate of future rewards γ maxₐ Q(sₜ₊₁, a) is the “temporal difference” update. The update is based on the best action maxₐ Q(sₜ₊₁, a), even if the agent did not actually choose that action (off-policy). This whole calculation just changes one entry in the table, refining the agent’s memory of how good a specific action in a specific state is (Q-Learning).